designing an ai extractor for enterprise data
ICD designed workflows and UI/UX for an AI extractor product that could be adapted and pitched across enterprise clients. The product helps teams upload large sets of documents, choose or create extraction templates, define the fields they want to capture, and turn unstructured files into structured, usable data. In this sample, the extractor is configured for property and related document data, helping users pull out locations, contact numbers, property details, prices, attachments and citations from dense PDFs. The goal was to make AI extraction feel reliable, reviewable and enterprise-ready, not like a black-box output.
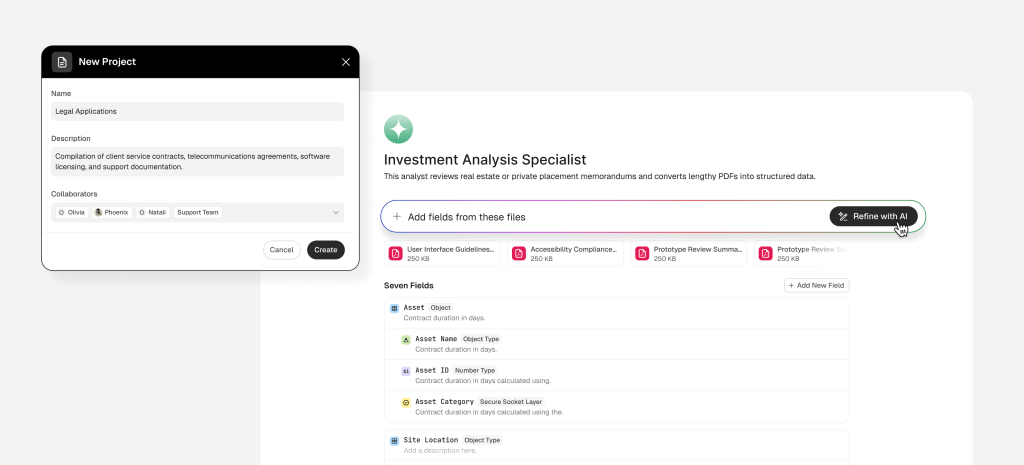
templates that make extraction reusable
The template gallery allows teams to start with purpose-built agents such as legal, finance or invoice analysis, or create a new project with their own field structure. This makes the product repeatable across industries: the same extraction system can be adapted for real estate, legal contracts, finance documents, invoices, support records or any enterprise dataset with recurring information patterns.

from documents to structured tables
The screens show a clear flow from file upload to extraction. Users can bring in documents from local files or connected apps, run an extraction agent, and see the results organised into tables with fields such as property, price, location and contact numbers. This turns scattered PDFs and attachments into searchable, comparable records that can be used by teams downstream.

evidence, citations and review built in
The product was designed to show not only what was extracted, but where it came from. Extracted values appear with document citations, page references, highlighted source text and editable field views, helping teams verify the result before trusting it. This mirrors the larger need in AI document systems: combining automated extraction with reviewability, structured outputs and source-linked confidence so enterprise users can act on the data safely.

partner-in-charge lisa rath | product design lisa rath, ujjawal aggarwal, arpit sharma, sreeja chatterjee, hariprasad, jatin kumar, vishnuprasad, DSV, lokesh parekh, pakhi dogra, bhumika chauhan, sakshi singh, garvit kumar, rahul mallik, prajakta chaudhuri